这个爬虫是在学习商业智能实训课程时留的作业,现在搬出来给大家分享。
爬取的链接为https://www.kugou.com/yy/rank/home/page1-8888.html(酷狗音乐排行)
先来看看网页结构:
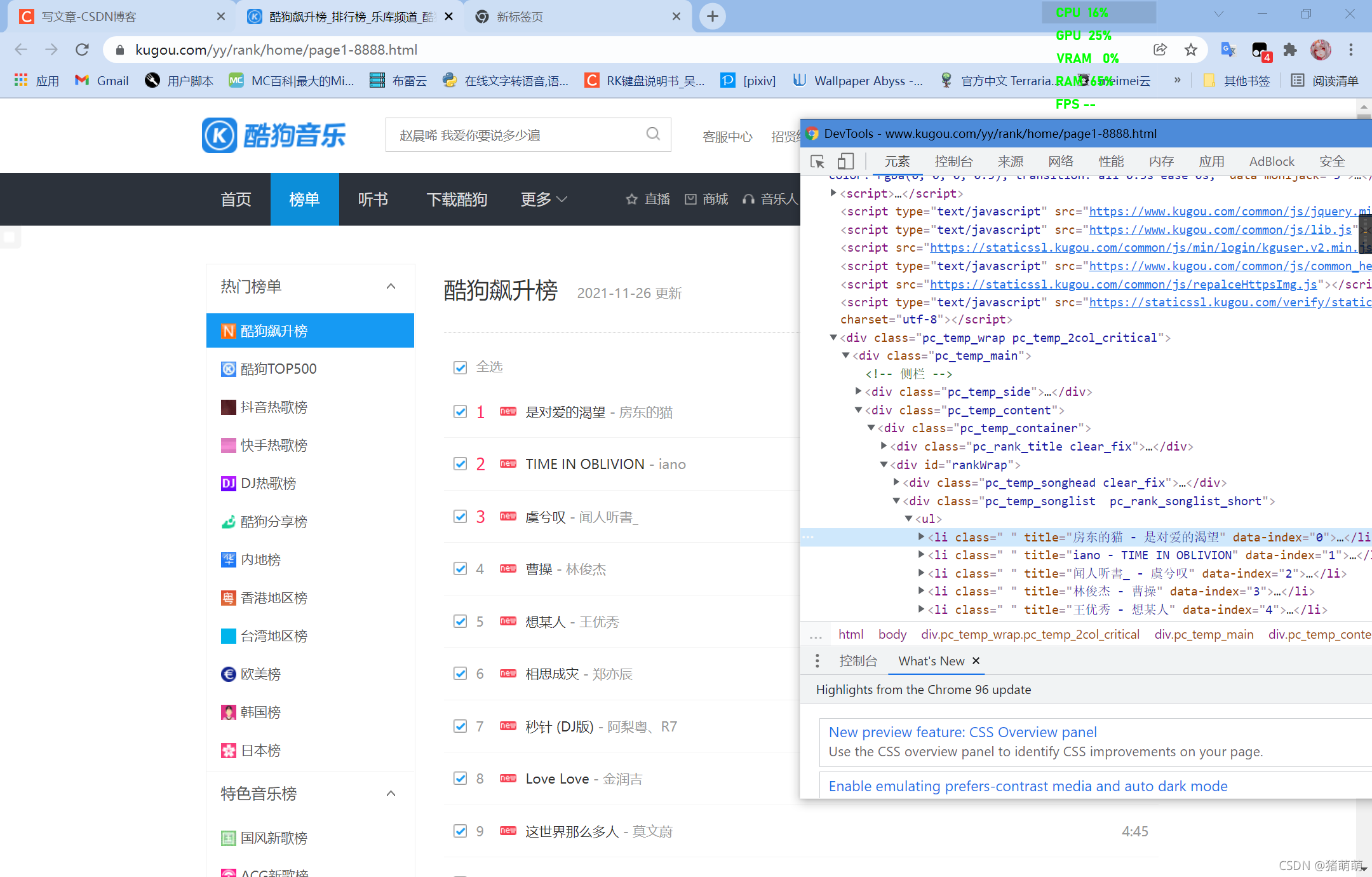
我们首先要知道我们的目的是什么,当然是获取歌曲的下载直链。然后就要开始构思我们的爬虫结构:
一、爬取歌曲排行榜的每一页的歌曲详情页链接+歌曲信息
二、根据每一个歌曲的详情页链接对歌曲的下载直链进行获取
三、通过下载直链对歌曲进行批量下载
那我们就开始构思爬虫第一步:
爬取歌曲排行榜的每一页的歌曲详情页链接+歌曲信息
在观察了网页结构以后,发现可以用bs4对网页进行解析,这个网页无任何反爬措施。
上程序:
```python
def SongInformation(page):
#调用函数传进来爬取页数
urls='https://www.kugou.com/yy/rank/home/'+page+'-8888.html'
re=requests.get(url=urls,headers=headers)
#save=re.content.decode('utf-8')
save=re.text
if save!=None:
#利用bs4进行网页解析
soup=bs(save,'html.parser')
#利用select组合查询器进行位置查询
rank=soup.select('span.pc_temp_num')#歌曲排名
musichref=soup.select('div.pc_temp_songlist>ul>li>a')#歌曲详情页链接
mhref=[]#歌曲链接
list=[]# 歌曲信息综合
singer = []#歌手名字
songname = []#歌曲名字
for i in musichref:
mhref.append(i['href'])#添加歌曲链接
list.append(i['title'].split(' - ',2))#添加歌曲作者以及歌曲名字
for i in list:
songname.append(i[1])#添加歌曲名字
singer.append(i[0])#添加歌手信息
for i,j,k in zip(mhref,songname,singer):
song_infor = {
'url':i,
'name':j,
'singer':k
}#压缩为song_infor字典对象
song_list_info.append(song_infor)#将song_infor字典存进数列
else:
pass
```在这一步过后,我们成功的获取到了歌曲的详情页链接,那么我们就要进行第二步:
根据每一个歌曲的详情页链接对歌曲的下载直链进行获取
先展示歌曲详情页网页效果(以《对爱的渴望》歌曲为例):
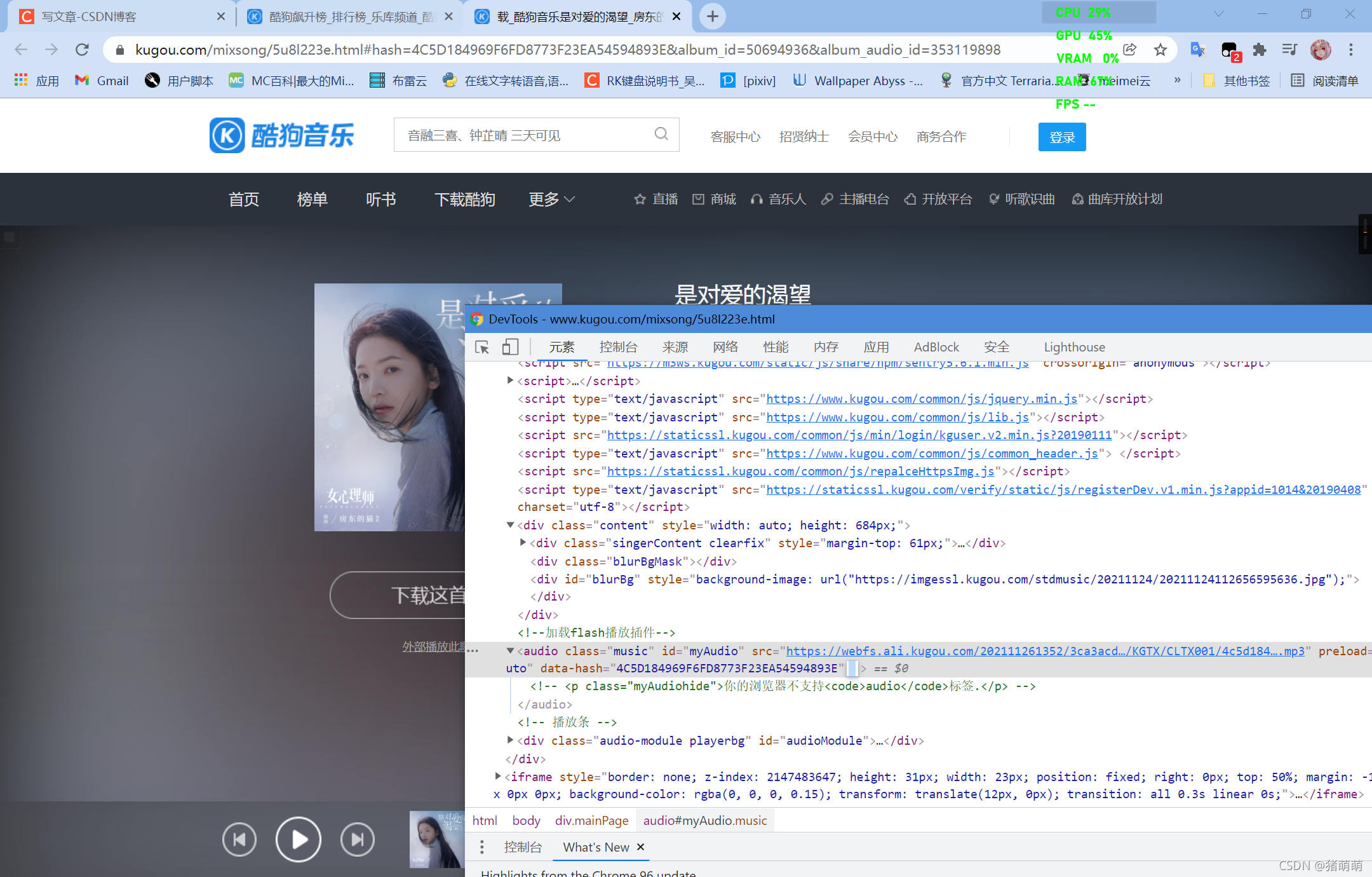
在这里我们可以看到歌曲的下载直链在一个叫做audio标签下边,此时出现了问题,通过bs4对网页进行解析,获取到的内容无audio。说明网站采取了部分反扒措施,那么我们则要通过selenium对网页信息进行获取,selenium的安装我就不在此阐述,详细教程直接百度即可。
废话不多说直接上代码:
```python
def down(url):
#传进来歌曲详情页的下载链接
option = webdriver.ChromeOptions()
#option.add_argument("headless")为selenium进行浏览器模拟时,不打开页面只在后台进行。
option.add_argument("headless")
#加载selenium
browser = webdriver.Chrome('E:\python\Scripts\chromedriver.exe', chrome_options=option)
#对网页进行解析
browser.get(url)
response=browser.page_source
#查找id为myAudio的标签
audiutl=browser.find_element_by_id('myAudio')
#硬核休息2s,防止被banIP
time.sleep(2)
#提取audiutl中的src属性值,并将其返回
print('*****************'+audiutl.get_property('src'))
return audiutl.get_property('src')
#browser.close()#关闭浏览器其他应用
```
这一步结束我们就获取到了我们的歌曲下载直链,接下来我们就可以对歌曲进行下载保存了。
通过下载直链对歌曲进行储存
这一步还是比较简单的,直接上代码:
```python
def KuGouDownload(startpage,endpage):
for i in range(startpage,endpage):
try:
print('正在存储第'+str(i+1)+'页歌曲信息')
#储存歌曲信息,对应第一步
SongInformation(str(i+1))
print('第'+str(i+1)+'页歌曲信息存储成功')
time.sleep(1)
except:
print('第'+str(i+1)+'页歌曲信息存储失败,已跳过当前页')
for i in song_list_info:
print(i['name'] + '下载地址:')
#获取下载直链,对应第二步
z=down(i['url'])
#通过下载直链将歌曲存储到本地
with open("D:\KugouSpider\下载音乐\{}.mp3".format(i["name"]), 'wb') as f:
mp3 = requests.get(z, headers=headers).content
f.write(mp3)
print('歌曲已下载完毕')
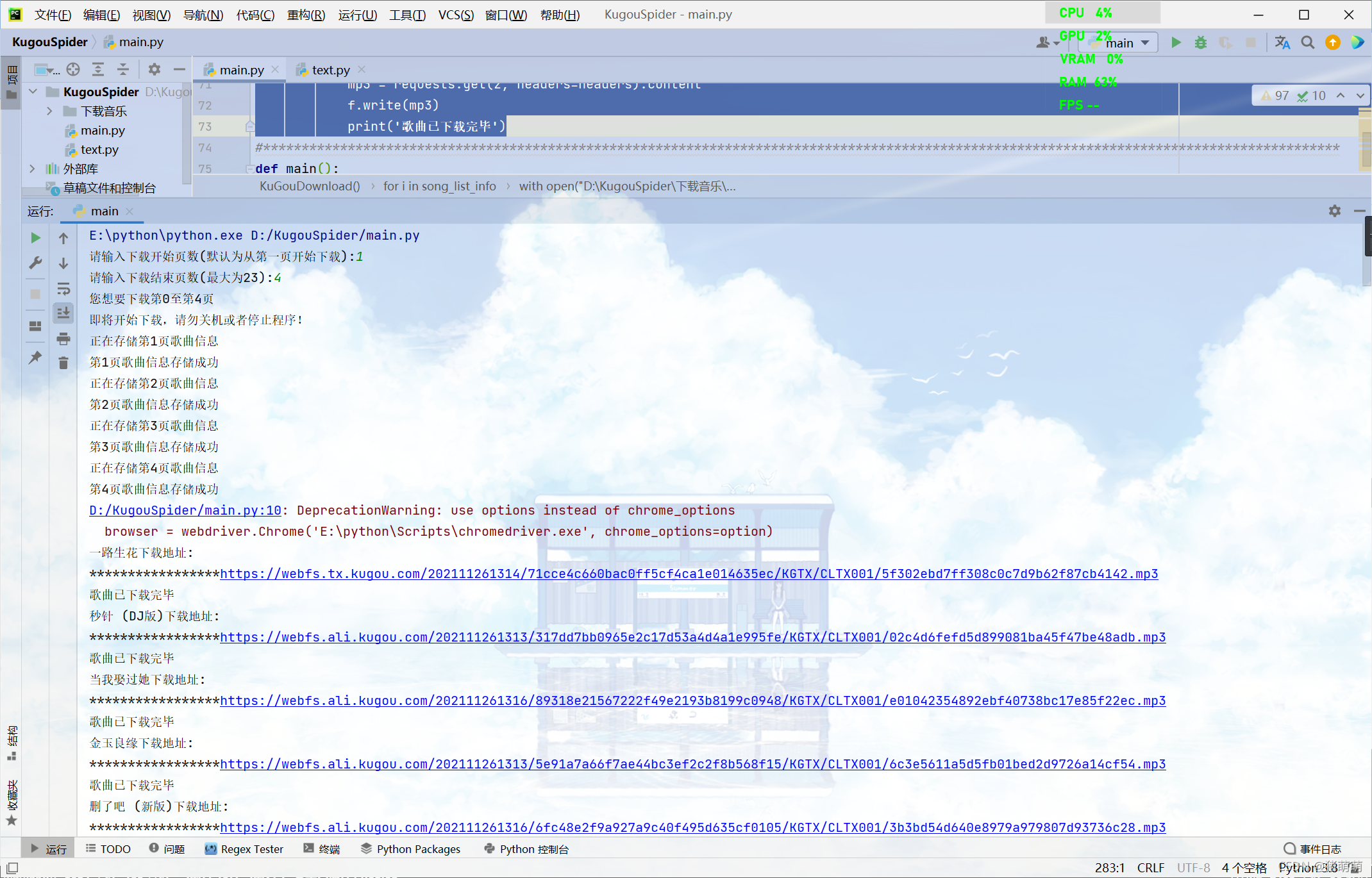
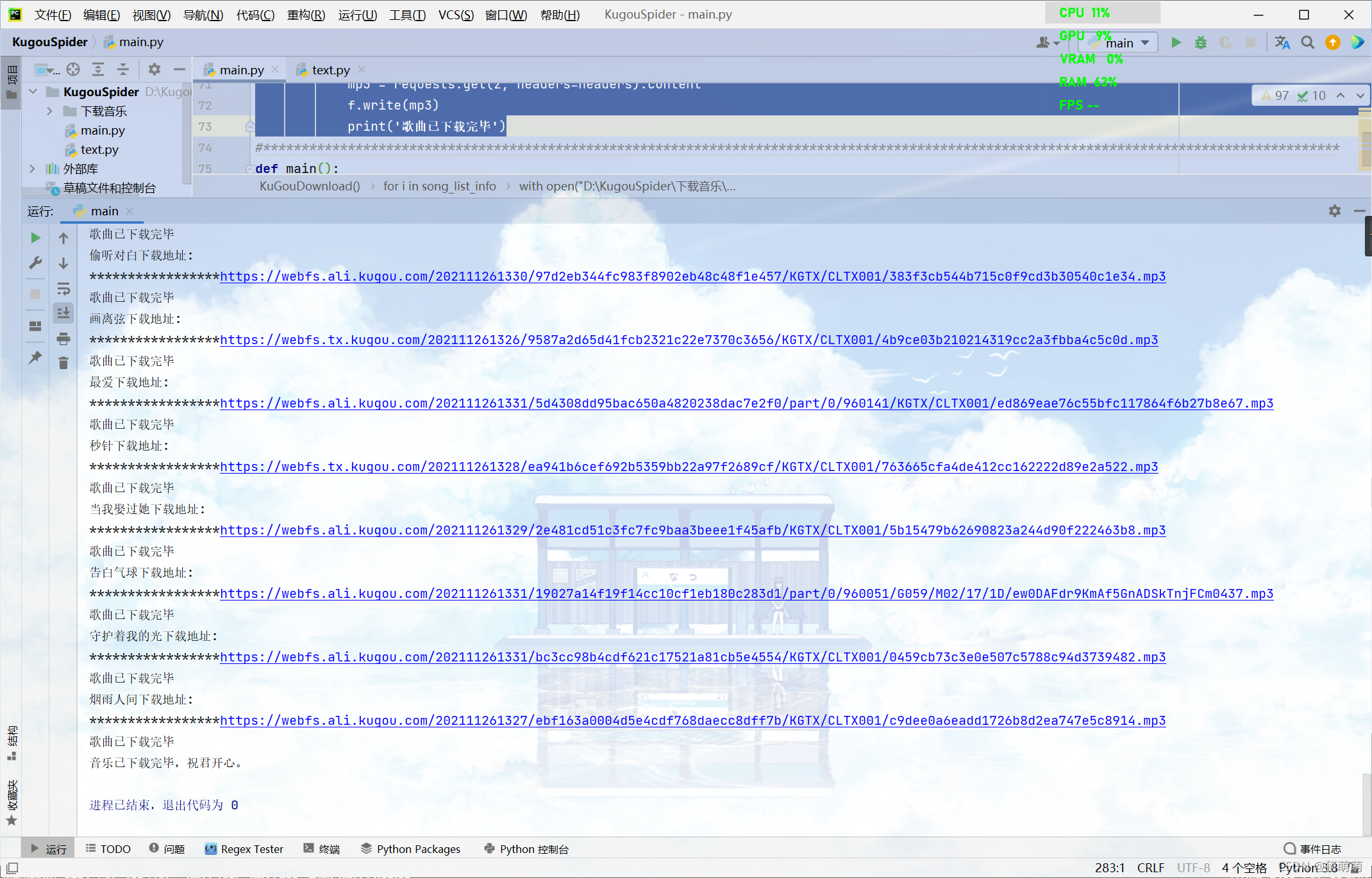
```这一步结束我们就完成了对酷狗音乐排行榜的歌曲爬取,下面展示运行过程效果图以及运行结果:
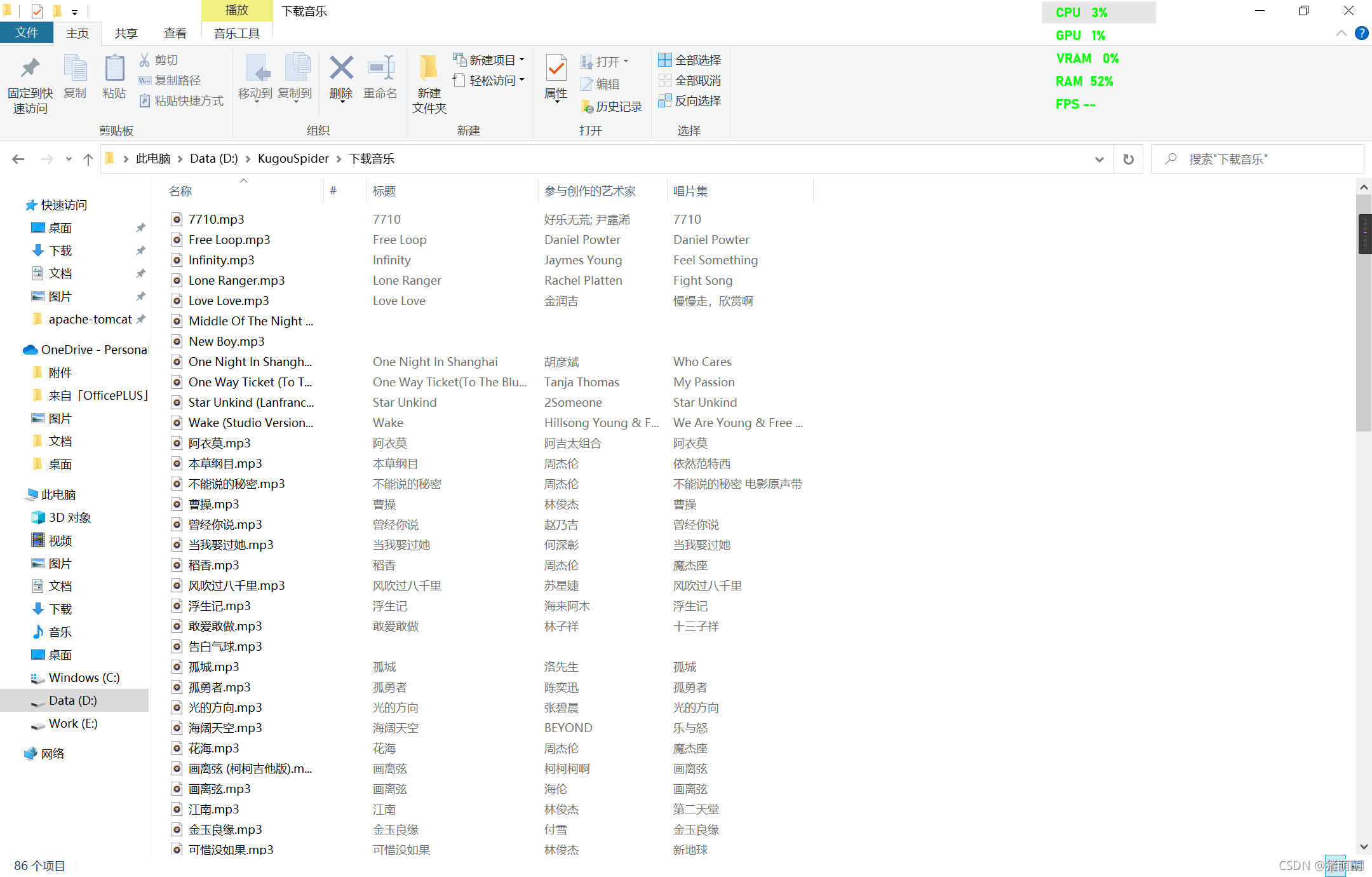
完整代码:
注意!!!!!要写一个公用请求头!!!!
```python
# -*- coding: utf-8 -*-
from bs4 import BeautifulSoup as bs
import requests
from selenium import webdriver
import time
# #此项目为爬取酷狗排行榜并批量下载的python项目
def down(url):
option = webdriver.ChromeOptions()
option.add_argument("headless")
browser = webdriver.Chrome('E:\python\Scripts\chromedriver.exe', chrome_options=option)
browser.get(url)#仍以阿衣莫为例
response=browser.page_source
audiutl=browser.find_element_by_id('myAudio')
time.sleep(2)
print('*****************'+audiutl.get_property('src'))
return audiutl.get_property('src')
#browser.close()#关闭浏览器其他应用
#*****************************************************************************************************************************************
#此方法为爬取歌曲信息:
song_list_info=[]#存放全部歌曲列表
song_download_url=[]#经过筛选处理后得到的真正的歌曲下载链接
headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36'
}#公用请求头
def SongInformation(page):
urls='https://www.kugou.com/yy/rank/home/'+page+'-8888.html'
re=requests.get(url=urls,headers=headers)
#save=re.content.decode('utf-8')
save=re.text
if save!=None:
soup=bs(save,'html.parser')
rank=soup.select('span.pc_temp_num')#歌曲排名
musichref=soup.select('div.pc_temp_songlist>ul>li>a')
mhref=[]#歌曲链接
list=[]# 歌曲信息综合
singer = []#歌手名字
songname = []#歌曲名字
for i in musichref:
mhref.append(i['href'])#添加歌曲链接
list.append(i['title'].split(' - ',2))#添加歌曲作者以及歌曲名字
for i in list:
songname.append(i[1])
singer.append(i[0])
for i,j,k in zip(mhref,songname,singer):
song_infor = {
'url':i,
'name':j,
'singer':k
}
song_list_info.append(song_infor)
else:
pass
#*****************************************************************************************************************************************
def KuGouDownload(startpage,endpage):
for i in range(startpage,endpage):
try:
print('正在存储第'+str(i+1)+'页歌曲信息')
SongInformation(str(i+1))
print('第'+str(i+1)+'页歌曲信息存储成功')
time.sleep(1)
except:
print('第'+str(i+1)+'页歌曲信息存储失败,已跳过当前页')
for i in song_list_info:
print(i['name'] + '下载地址:')
z=down(i['url'])
#print('************'+z)
#z=song_download_url.append(down(i['url']))
with open("D:\KugouSpider\下载音乐\{}.mp3".format(i["name"]), 'wb') as f:
mp3 = requests.get(z, headers=headers).content
f.write(mp3)
print('歌曲已下载完毕')
#********************************************************************************************************************************************
def main():
try:
a=input('请输入下载开始页数(默认为从第一页开始下载):')
if a==''or a=='1':
a=0
else:
a=int(a)
b=input('请输入下载结束页数(最大为23):')
b=int(b)
#if b>23
print("您想要下载第"+str(a)+'至第'+str(b)+'页')
print('即将开始下载,请勿关机或者停止程序!')
KuGouDownload(a,b)
print('音乐已下载完毕,祝君开心。')
except:
print('您输入的信息有误,请重新运行此程序。')
if __name__ == '__main__':
main()
```