在前一阵子,学习了bs4以后,我想这去找个网站测试一下能否对数据进行爬取,经过查看,我选择了无忧书城。
本爬虫已经实现了爬取武侠板块的小说并按照书名存储进相应的文件夹,每一章存储为单独的txt文件的功能。其实可以在对这个爬虫进行再次开发,可以将此网站的全部资源进行爬取存储。
废话不多说,开始介绍爬虫代码:
首先是程序流程:
- 爬取武侠小说板块每本书对应的链接,并进行存储
- 根据爬下的单本书的链接进入到书籍目录页(此超链接以《千门》小说为例),对每一章的阅读链接进行爬取。
- 根据传进来的每一章的阅读链接对小说内容进行爬取并存储。
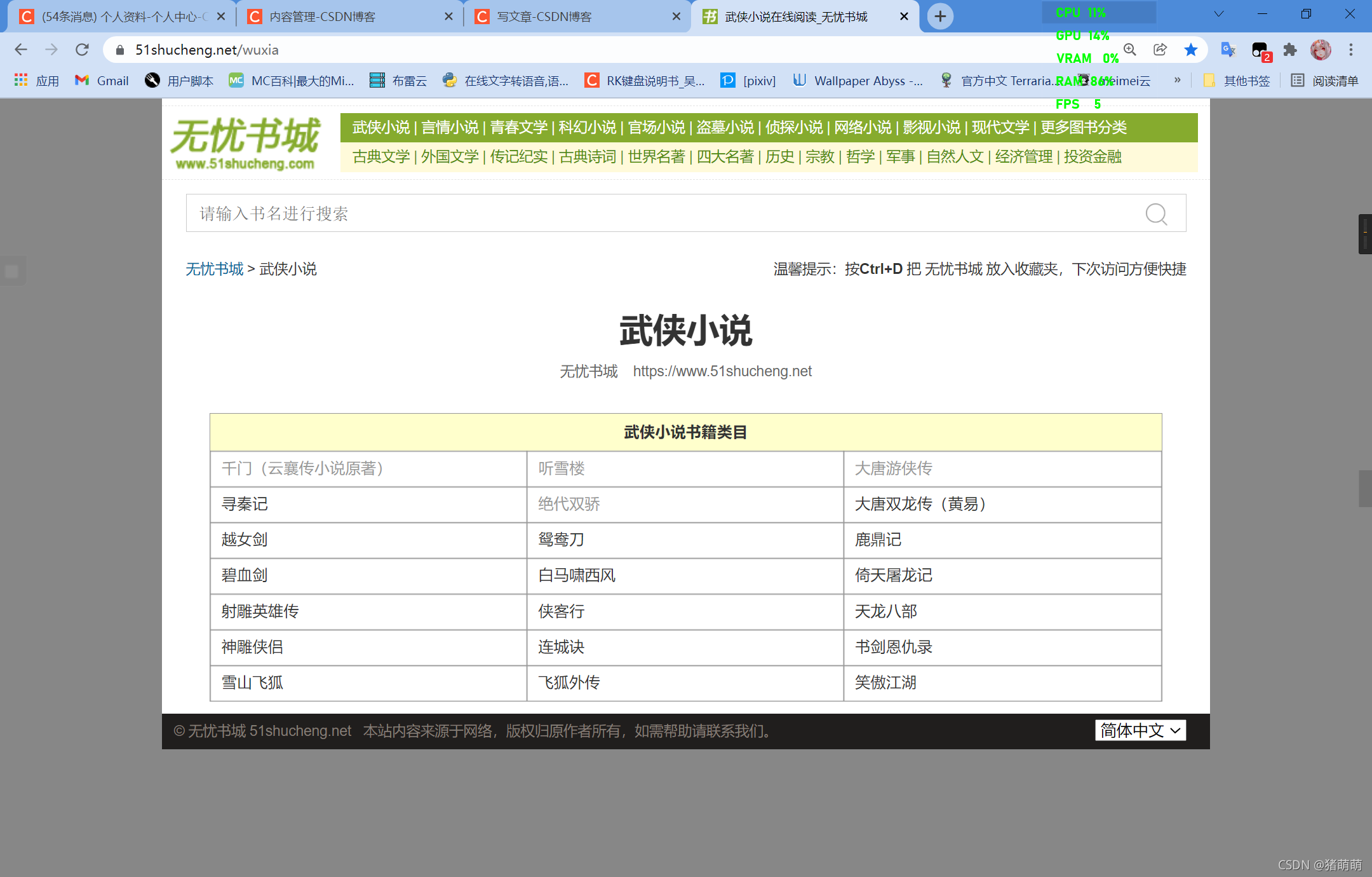
爬取武侠小说板块每本书对应的链接
网页效果图:
接下来就是所对应的程序设计:
def novel_name_url():
#爬取小说链接
url = 'https://www.51shucheng.net/wuxia'
#请求头
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36'
}
#利用BS4对网页进行解析
soup = requests.get(url=url, headers=headers)
save = soup.content.decode('utf-8')
shuju = bs(save, 'html.parser')
#通过select组合查询定位链接所在的位置
a=shuju.select('div.mulu-list>ul>li>a')
#进行遍历存储
for i in a:
novel_url.append(i['href'])#提取其中的href链接
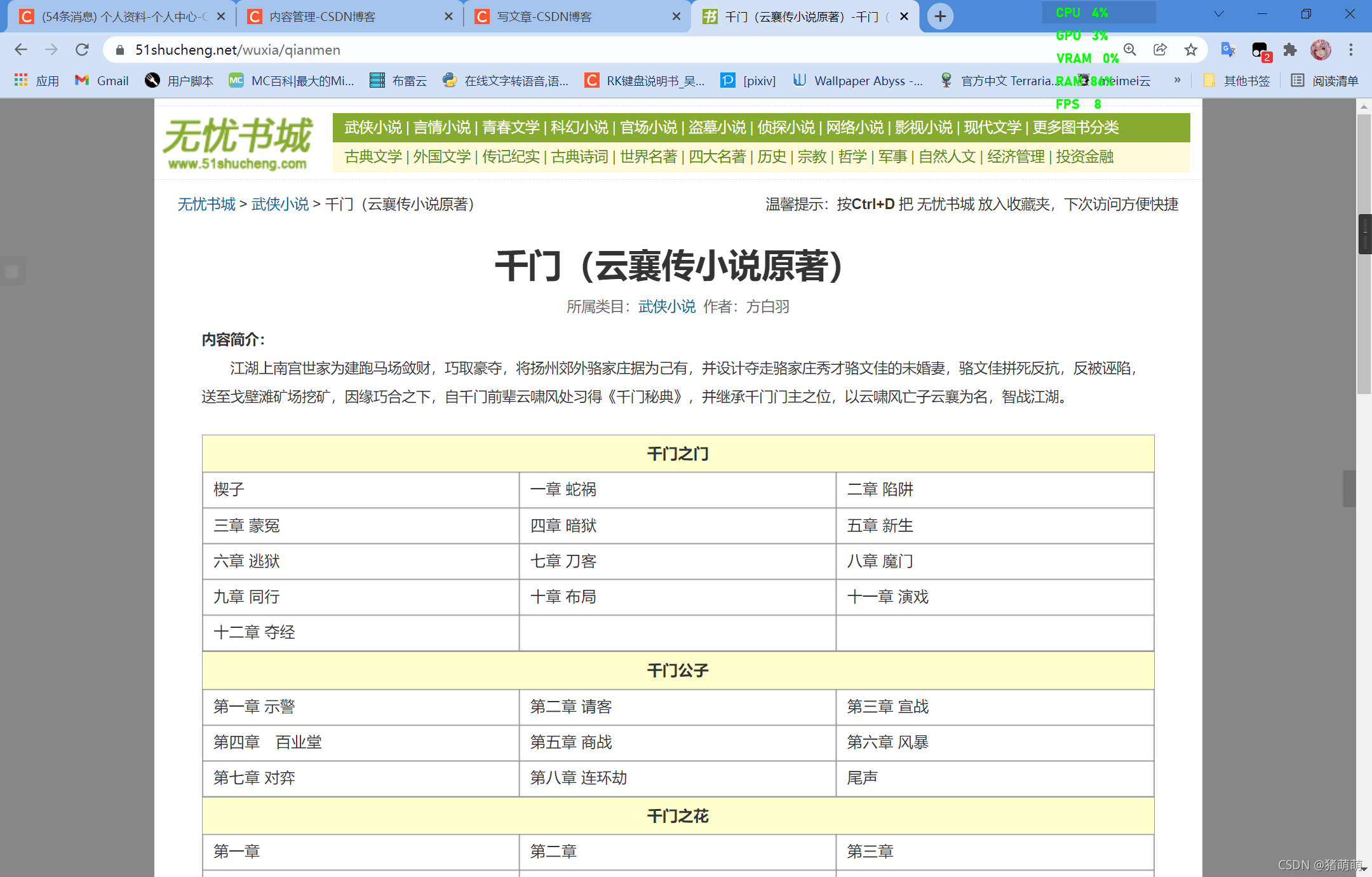
novel_name.append(i.get_text())#获取小说名字根据爬取的书籍链接对书籍目录进行爬取
网页效果图:
所对应的爬虫程序设计:
def novel_chapter_url(urls):
#爬取每一小说章节链接
#urls='https://www.51shucheng.net/wuxia/xueshanfeihu'
#请求头
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36'
}
#利用BS4对网页进行解析
soup = requests.get(url=urls, headers=headers)
save = soup.content.decode('utf-8')
shuju = bs(save, 'html.parser')
#对应目录的位置名字有两种,所以设计了两种搜索路径,一种为:div.mulu-list>ul>li>a,另一种div.mulu-list-2>ul>li>a为:
a=shuju.select('div.mulu-list>ul>li>a')
#如果a模式搜索不到目标即a的长度为0,那么则再次采用div.mulu-list-2>ul>li>a进行查询
if len(a) == 0:
a = shuju.select('div.mulu-list-2>ul>li>a')
shuju = []
#将数据进行遍历存储
for i in a:
xiaoshuo_info = {
'title': i['title'],#将目标中的title属性进行存储
'href': i['href']#将目标中的href属性进行存储
}
shuju.append(xiaoshuo_info)#将存储字典存进shuju数列里
return shuju#将数据返回根据获取的每一章的链接对小说内容进行存储
老样子,先上网页效果图:
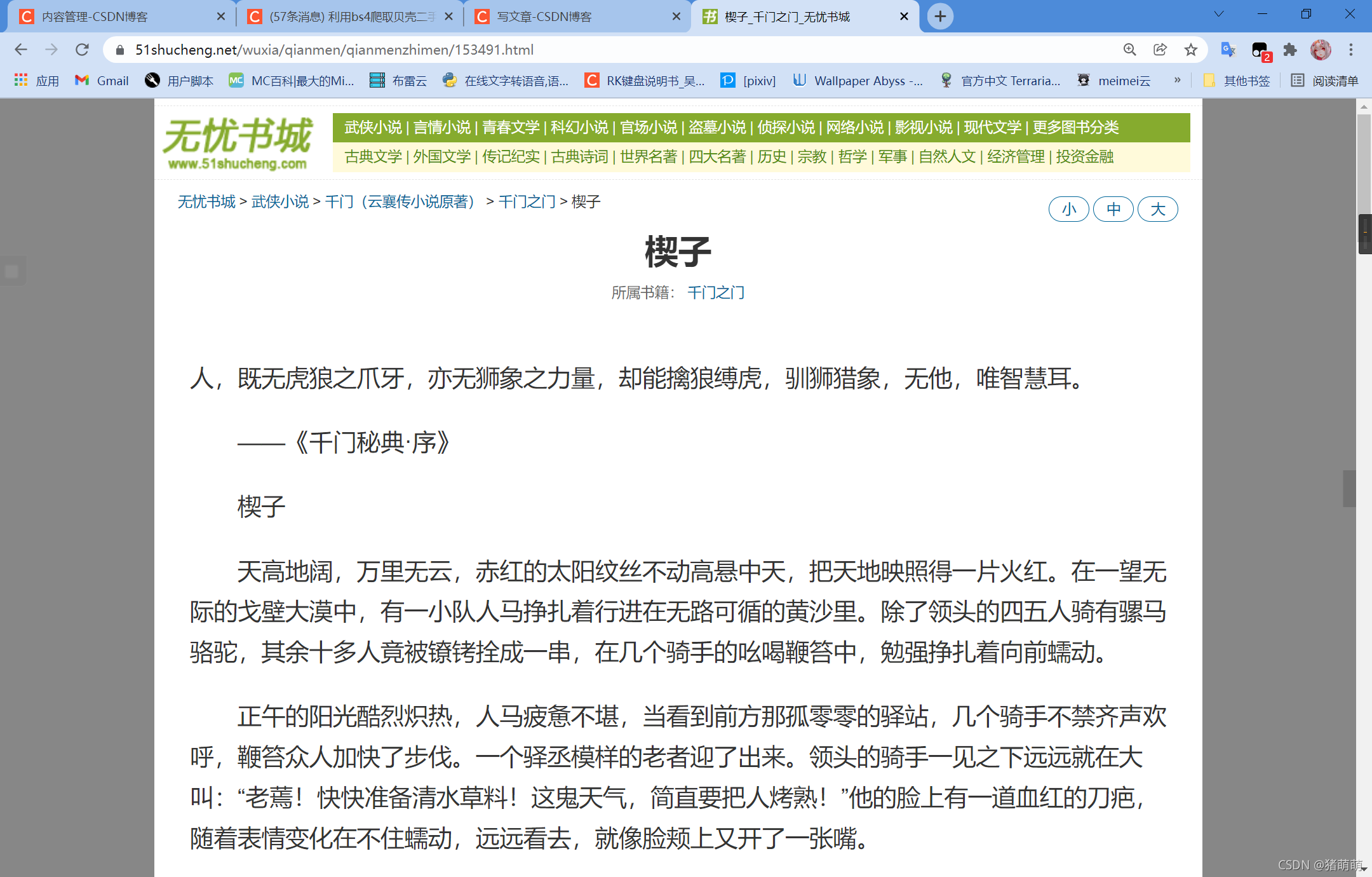
这个页面设计爬虫比较简单:
def novel_text(path,name,url):
#爬取每一章小说具体内容
#url="https://www.51shucheng.net/wuxia"
#打印传进来的路径
print(path)
#日常请求头
headers={
'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.54 Safari/537.36'
}
#利用BS4对网页进行解析
soup=requests.get(url=url,headers=headers)
save=soup.content.decode('utf-8')
shuju=bs(save,'html.parser')
#利用select组合查询器定位
a=shuju.select('div.neirong>p')
#根据路径创建相应名字的txt文件并将小说内容进行存储
with open(path+"\{}.txt".format(name),'w') as f:
for i in a:
f.write(i.get_text())#将内容存储进文件
f.write('\r\n')#还原网站样子,对文件进行换行,不然存进去就是一行字,超长的那种主函数的设定!!!
代码如下:
if __name__ == '__main__':
#文件存储路径
path = 'D:\Textspider'
# <1>主页下的分类专区名称以及链接
partition_name = []
partition_url = []
# <2>分类专区下的具体书名以及链接
novel_name = []
novel_url = []
# <3>书籍信息下的章节名称以及链接
novel_info=[]
#进行信息存储
novel_name_url()
for i,j in zip(novel_name,novel_url):
print(i+':'+j)
for i,j in zip(novel_name,novel_url) :
print('正在存储'+i+'信息')
#根据爬取的书籍链接对目录链接进行爬取
z=novel_chapter_url(j)
print(z)
info={
'name':i,
'href':j,
'info':z
}
#防止被封IP,硬核休息2s
time.sleep(2)
#将链接存储进novel_info
novel_info.append(info)
print(i+'信息存储成功')
#根据存储信息进行数据爬取
for i in novel_info:
z=path+'\\'+i['name']
try:
#判断路径是否存在,如果不存在,则进行路径创建
if not os.path.exists(z):
os.mkdir(z)
print(z + '已创建')
else:
print(z+'路径已存在')
except Exception as e:
print(z+'路径创建失败或者路径已存在')
print('错误信息:'+e)
print('存储路径:' + z)
for j in i['info']:
print(j)
title=j['title']
href=j['href']
#用try包围,有时会因为网络情况导致爬取失败
try:
print('小说标题:'+title)
print('下载路径:'+href)
novel_text(z, title, href)
print(j['title'] + '已下载完成!!!')
#硬核休眠5s
time.sleep(5)
except:
print(j['title'] + '下载失败')爬取过程效果图:
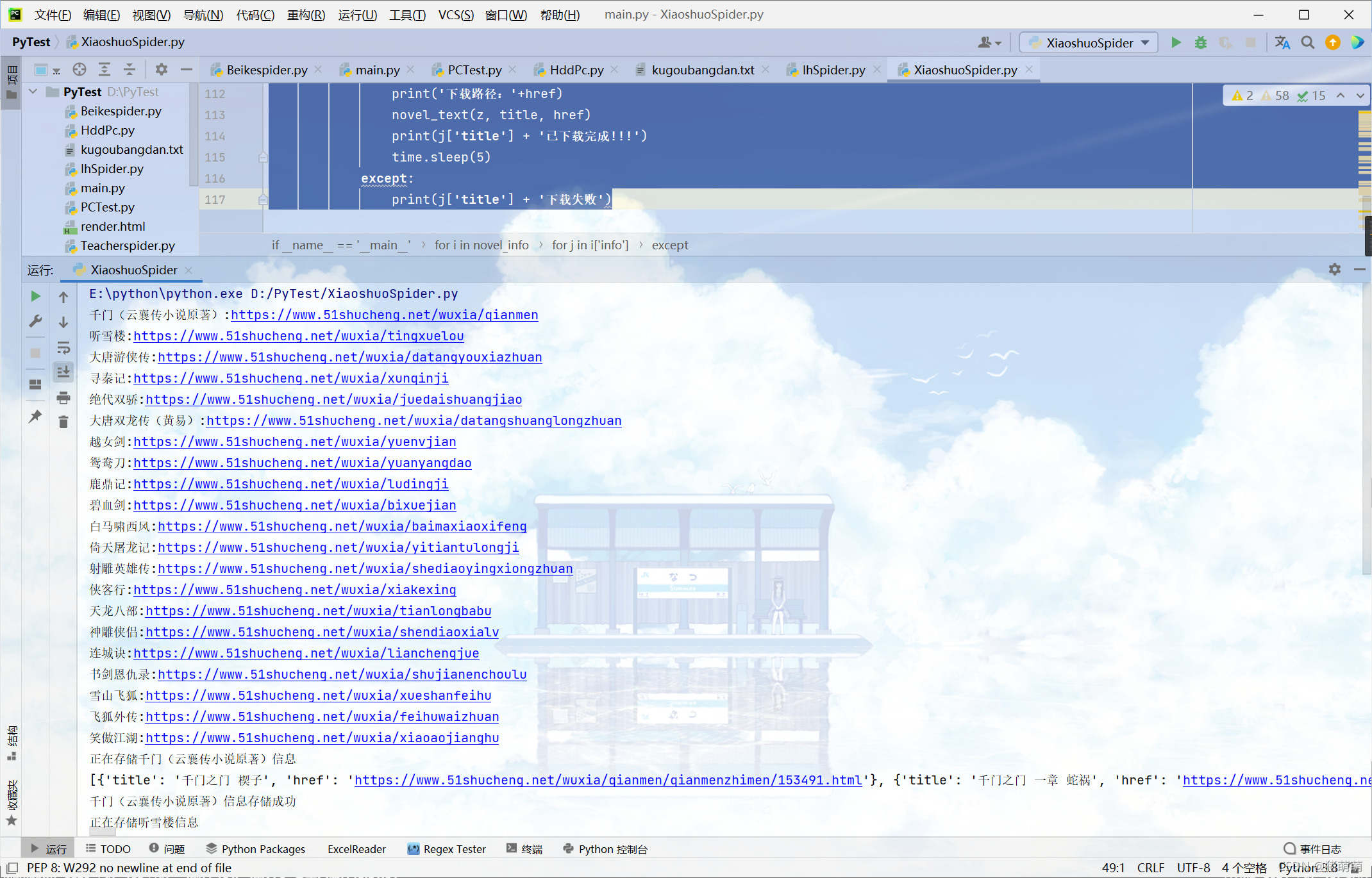
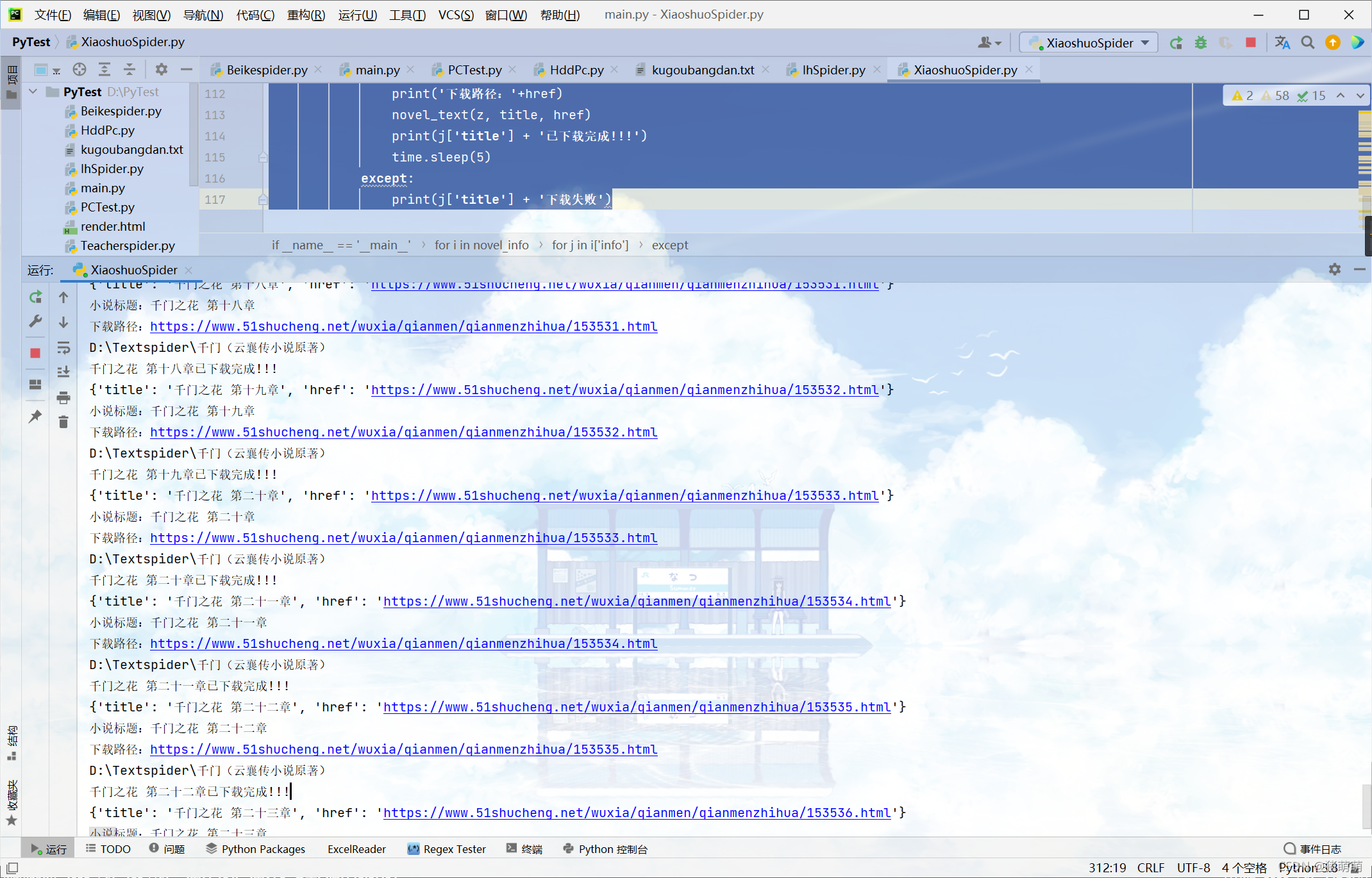
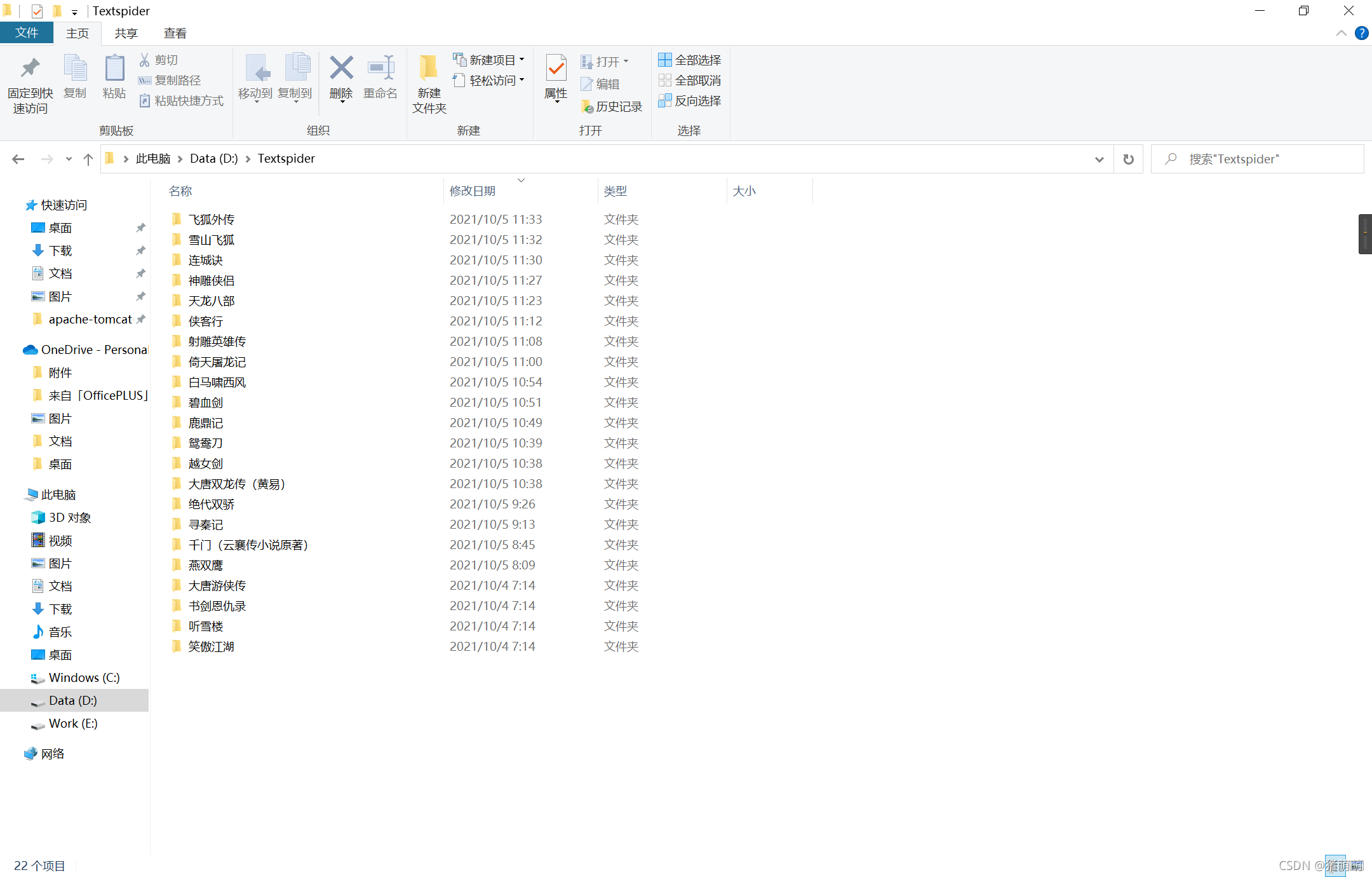
每本书所对应文件夹内存有相应的小说文件:
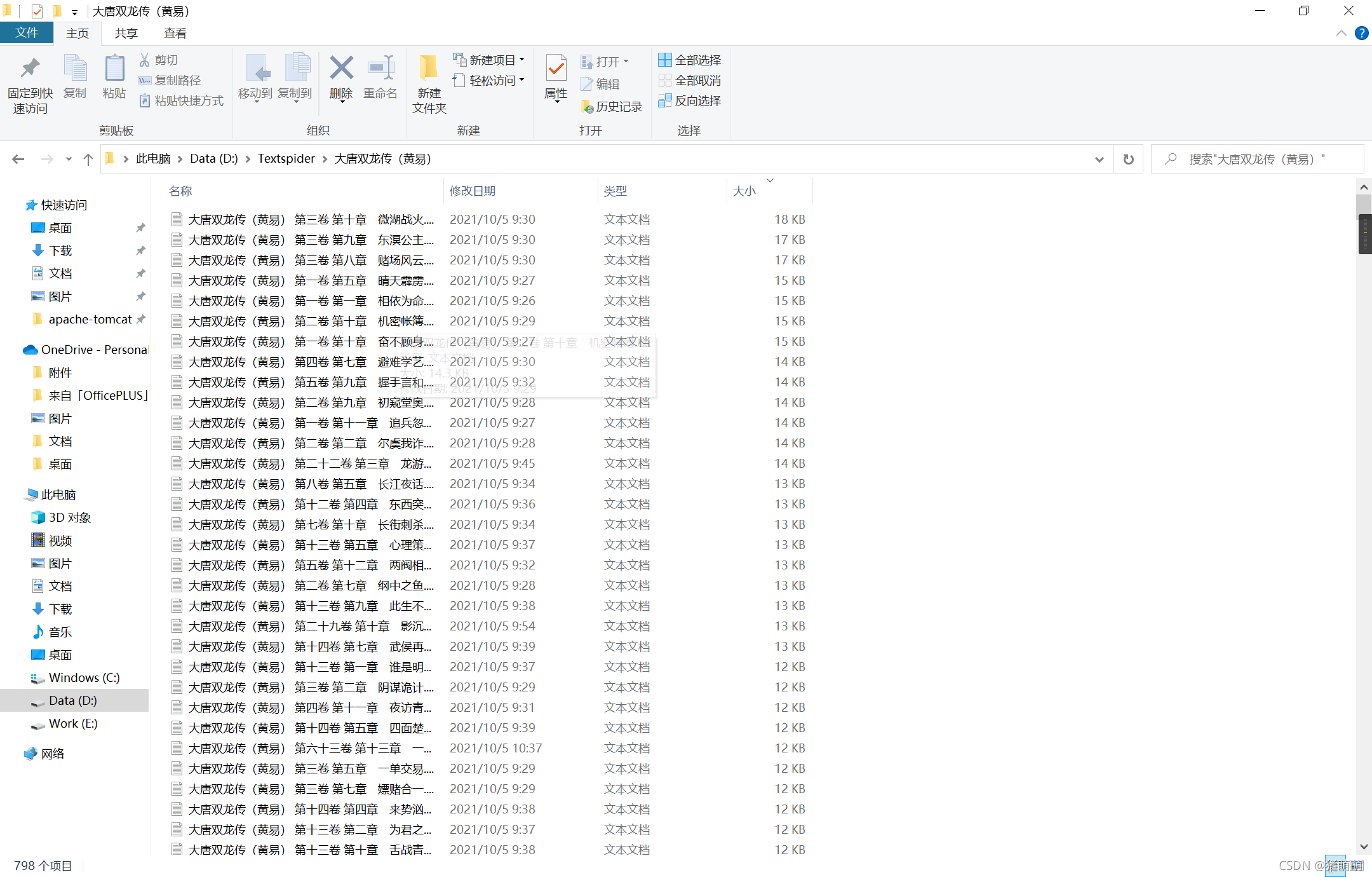
爬取速度较慢,因为内容太多。
希望能够对您有所帮助 本着分享代码的原则为大家免费下载,无需积分,点击此处进行下载资源跳转
2022-04-18更新:
项目上传了Github,项目地址为:https://github.com/ZhuMengMeng666/spider_collection
里面的XiaoshuoSpider.py就是此项目的py文件。