一、下载 Node.js
访问 [Node.js](https://nodejs.org/zh-cn/官网, 下载长期维护版即可.
下载完成后安装, 无脑下一步即可.
二、开始转换
访问你的 WordPress 后台, 导出 xml 文件, 选择所有内容, 否则无法导出图片.
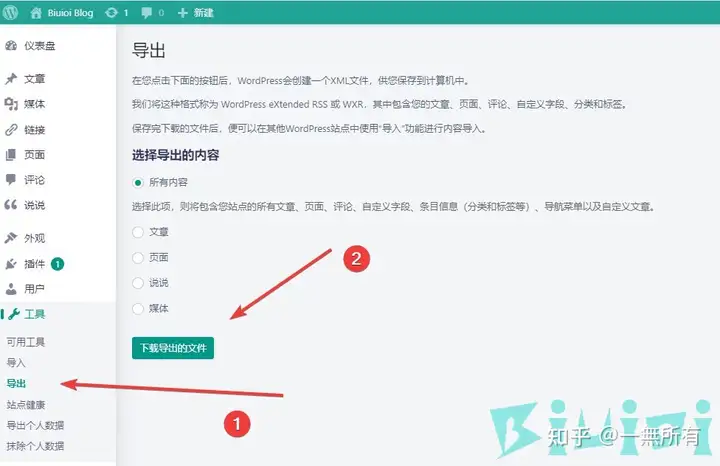
新建一个文件夹, 名字随便, 把刚才下载的 .xml 文件改名为 export.xml 放到此文件夹.
按住 Shift 右键文件夹空白处打开 powershell
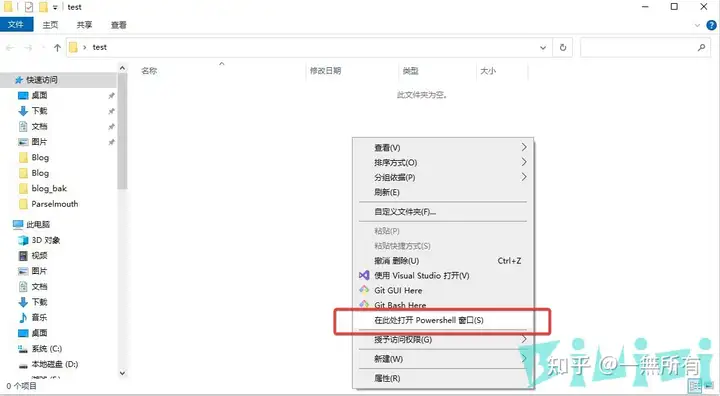
输入命令
npx wordpress-export-to-markdown
回车下一步, 提示 (y/N) 全部选 y 即可.
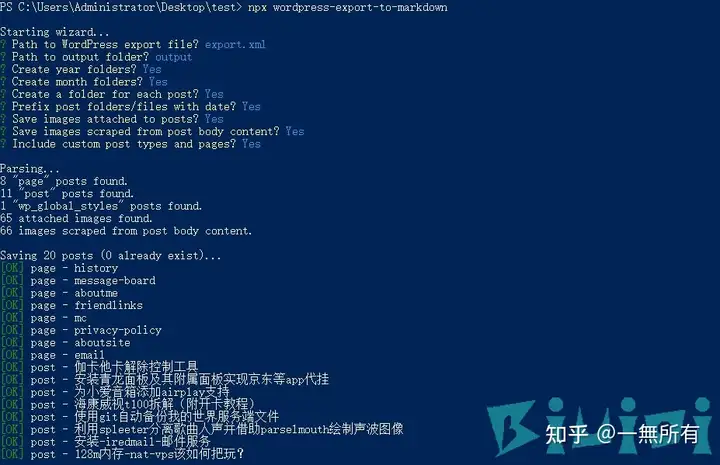
这样就算执行成功了(忽略我那两个错误), 返回文件夹 output 就是导出的所有内容.
可以打开预览一下, 所有图片的链接的被替换到了本地.
最后运行我写的python垃圾代码(能用就行doge):
import os
import re
import requests
def find_md_files_deep_recursively(folder_path):
md_files = []
for root, dirs, files in os.walk(folder_path):
for file in files:
if file.lower().endswith(".md"):
md_files.append(os.path.join(root, file))
return md_files
def find_images_in_md_file(md_file_path):
images = []
image_pattern = r"!\[.*?\]\((.*?)\)" # 匹配 Markdown 图片链接的正则表达式
with open(md_file_path, "r", encoding="utf-8") as file:
content = file.read()
matches = re.findall(image_pattern, content)
for match in matches:
if match.startswith("http://") or match.startswith("https://"):
images.append(match)
return images
def find_images_recursively(folder_path):
md_files = find_md_files_deep_recursively(folder_path)
images = {}
for md_file in md_files:
images_in_md = find_images_in_md_file(md_file)
if images_in_md:
images[md_file] = images_in_md
return images
def merge_images_data(images_data_list):
merged_images_data = {}
for images_data in images_data_list:
for md_file, images in images_data.items():
if md_file not in merged_images_data:
merged_images_data[md_file] = []
merged_images_data[md_file].extend(images)
return merged_images_data
def download_file(url, target_path):
if not os.path.exists(target_path):
# 文件不存在,进行下载
response = requests.get(url)
if response.status_code == 200:
with open(target_path, 'wb') as file:
file.write(response.content)
print(f"下载成功:{target_path}")
else:
print(f"下载失败,状态码:{response.status_code}")
else:
print(f"文件已存在,取消下载:{target_path}")
def replace_text_in_md_file(file_path, original_text, replacement_text):
with open(file_path, 'r', encoding='utf-8') as file:
content = file.read()
modified_content = content.replace(original_text, replacement_text)
with open(file_path, 'w', encoding='utf-8') as file:
file.write(modified_content)
if __name__ == "__main__":
folder_path = "D:\\wordpress-markdown\output\post" # 替换为目标文件夹路径
images_data_list = []
for root, dirs, files in os.walk(folder_path):
for dir in dirs:
images_data = find_images_recursively(os.path.join(root, dir))
images_data_list.append(images_data)
merged_images_data = merge_images_data(images_data_list)
for md_file, images in merged_images_data.items():
print(f"Markdown 文件:{md_file}")
if not os.path.exists(md_file.split("index.md")[0]+"images\\"):
os.makedirs(md_file.split("index.md")[0]+"images\\")
for image in images:
print(image.split(" ")[0].split("?")[0])
download_file(image.split(" ")[0],md_file.split("index.md")[0]+"images\\"+image.split(" ")[0].split("?")[0].split("/")[-1].replace(":", "_"))
replace_text_in_md_file(md_file,image.split(" ")[0],"images\{}".format(image.split(" ")[0].split("?")[0].split("/")[-1].replace(":", "_")))附上效果图

